
AWS Static Hosting - Part 02: CloudFront Edge Functions
In the previous article we discuss how we can put together AWS CloudFront, S3 bucket and other associated services using Terraform to host our static website. We now need to make our site SEO-friendly, especially if it contains dynamic content.
| AWS Static Hosting (2 Part Series) |
|---|
| AWS Static Hosting - Part 01: CloudFront, S3 and Terraform |
| AWS Static Hosting - Part 02: CloudFront Edge Functions |
Before we get started, let’s discuss some theory.
What does it mean: Pre-rendering a website
When a web crawler visits a website, it follows the same process as a regular user’s browser: it sends request to the website’s server, and in response, the server sends back the necessary files, such as HTML, CSS, JavaScript, and images. The web crawler uses this information to build an index of the website’s content, which allows search engines to provide relevant results to users when they conduct searches.
Now, to speed up this indexing process and provide a more efficient experience for search engines. This is when pre-rendering comes into play. Pre-rendering involves sending a pre-rendered static HTML version of the webpage to the web crawler instead of just the server-side files. The pre-rendered version already contains all the essential content and is ready for the web crawler to process without the need for further rendering.
By providing a pre-rendered HTML version of the page to web crawlers, websites can ensure that search engines can quickly and accurately index their content. This can lead to better visibility in search engine results and an overall improved SEO (Search Engine Optimization) performance. It’s a technique that benefits both the website owners and the search engines, as it allows for more efficient indexing and faster access to relevant content for users conducting searches.
How we going to implement this?
As we are clear now what is Prerendering, we shall conquer what solution we going to use.
There are more than hand full of solutions that we can use in this case, in fact, you should be able to come up with your own solution using your favorite programming language. But here we use, prerender.io as our solution.
You can host it on your own infrastructure if you wish, you can follow the document here.
For this article, I am going to use their cloud offering, which has a free tier.
Let’s see what happen under the hood
First, before we dig deeper into the solution, let’s clarify a couple of basics.
Request categories
Base on our context, we can categories requests to the web site based on client,
- Browser client: This is a regular human user
- Crawler: Web crawlers or bots who are visiting to website
- Prerender crawlers: Crawlers from Prerender services
So how can we identify them?
Browser clients and crawlers can be easily identified by looking at the user-agent header. In terms of the Prerender service, Prerender service itself sends a x-Prerender header along with the request, so we can use that header.
CloudFront event and lambada at edge integration
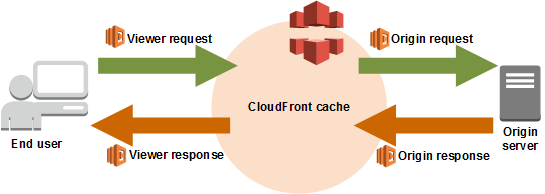
In summary, by linking a CloudFront distribution with a Lambda@Edge function, CloudFront gains the ability to capture and handle requests and responses at its edge locations. This integration enables the execution of Lambda functions triggered by specific CloudFront events. These events encompass different stages in the request-response cycle:
- Viewer request event: This occurs when CloudFront receives a request from a viewer, meaning a user or a client attempting to access content through CloudFront.
- Origin request event: Before CloudFront forwards a request to the origin, this event takes place. The origin refers to the source server that holds the actual content being requested.
- “Origin response” event: CloudFront triggers this event when it receives a response from the origin server. The response contains the requested content.
- Viewer response event: This event happens just before CloudFront sends the response back to the viewer, ensuring any required modifications or customizations can be applied.
Refer this for further information.
Alright, back to the original solution discussion.
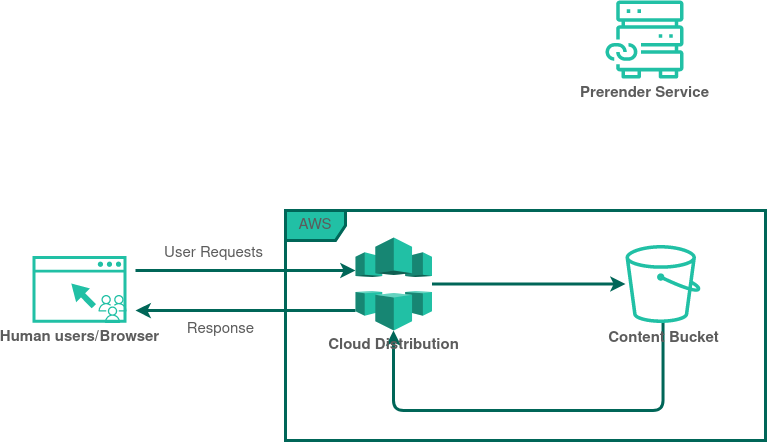
Ordinary Browser requests
Crawlers and Prerender request
Let’s discuss what happens to the requests from crawlers. Let’s assume that the particular request has never been cached in Prerender.
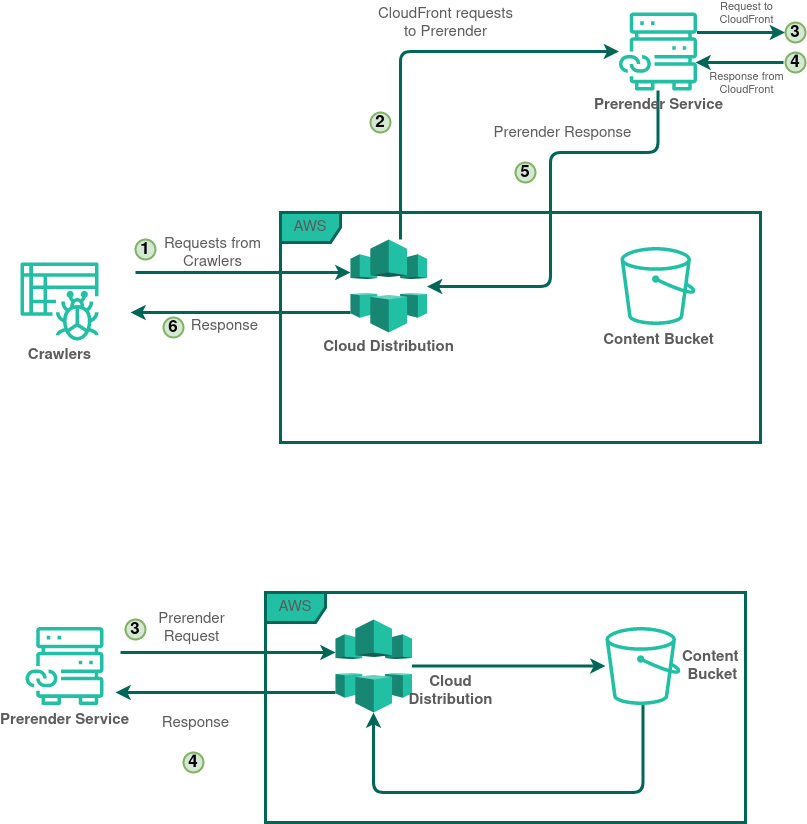
- Request from a crawler hit the CloudFront distribution
- CloudFront verify that it is a crawler, and it is not from Prerender
- Then CloudFront talks to Prerender (I have a request from a crawler, please pass me the static/rendered webpage)
- Then Prerender, hold the current request from CloudFront, and send a brand-new request to CloudFront
- Now, CloudFront validate that this request is from Prerender
- CloudFront would serve this request from Prerender as a normal user requests
- Then Prerender render the content and respond to the CloudFront with static/rendered (HTML) web content
- Finally, CloudFront respond to the Crawler with the static content from Prerender
Error Handling
Let’s take a brief look at error handling. Suppose a request is made for a page that isn’t available. Web servers typically return a “not found” page with or without 404 HTTP status code. Prerender should not cache these 404 pages, neither let search engines to index them; in such a case, we should inform the crawler that the request isn’t valid.
To address this Prerender offers a very cool solution 💡. You can embed the error code into your HTML using meta tags, allowing Prerender to detect and relay it back. In other words, you can map a HTTP status code using HTML meta tags.
For more information, see here.
We will discuss this more with an example code later in this article.
Implementation
Before diving deep into the code, I’d like to touch upon the setup. In the subsequent sections, I’ll reference our aws-edge-functions repository.
This repository to be used as a Terraform sub-module with the AWS Static Hosting module mention here. The primary focus of this module is to deploy our Lambda@Edge functions, facilitating Prerender integration with CloudFront.
The repository can be divided into two sections,
- Terraform IaC dedicated to the edge function deployment
- A monorepo for the edge functions and their development and build configuration
Terraform IaC for edge function deployment
Now, let’s narrow our focus to the Terraform code, setting aside the Prerender and the theoretical aspects discussed earlier.
Our objective is to deploy a series of AWS Lambda functions. In this particular context,
- first, we must build the code
- then, we can package and upload it as a Lambda function (AKA deploy).
Assume all build configurations have been preset for us. All we’d need to do is run a specific build command, which will compile (transpile to be exact) the code.
The function below executes the build command each time we run the terraform apply command. Here, we’ve defined two null resources with some local provisioners:
- To verify the presence of Node
- To install dependencies and build the code.
# build.tf
resource "null_resource" "check_node_version" {
triggers = {
always_run = timestamp()
}
provisioner "local-exec" {
command = "npx yarn version --non-interactive"
working_dir = "${path.module}/${var.edge_function_path}"
interpreter = ["bash", "-c"]
on_failure = fail
}
}
resource "null_resource" "build_edge_functions" {
triggers = {
always_run = timestamp()
}
provisioner "local-exec" {
command = "npx yarn install --non-interactive && npx yarn build"
working_dir = "${path.module}/${var.edge_function_path}"
interpreter = ["bash", "-c"]
on_failure = fail
}
depends_on = [null_resource.check_node_version]
}A Quick Note: For this setup, I’m leveraging a pipeline to deploy the infrastructure. I’ve chosen Spacelift for this purpose. If you’ve been following along from the previous article, you might recall the GitHub repo associated with Article 01. Within that repo, you’ll find a Dockerfile 🤔.
Why is this Dockerfile significant? Spacelift offers the capability to pair custom build environments with its runners. So, I’ve incorporated Node.js and npm into the runner’s environment.
# https://github.com/krishanthisera/aws-static-hosting/blob/main/Dockerfile
FROM public.ecr.aws/spacelift/runner-terraform:latest
USER root
# Install node and npm
RUN apk add --update --no-cache nodejs npm
USER spaceliftNow, we need to create a role and associate it with the Lambda function. This step enables us to utilize our Lambda functions as Lambda@Edge functions:
# data.tf
data "aws_iam_policy_document" "lambda_edge_assume_role_policy" {
statement {
sid = "LambdaEdgeExecution"
effect = "Allow"
actions = ["sts:AssumeRole"]
principals {
type = "Service"
identifiers = ["lambda.amazonaws.com", "edgelambda.amazonaws.com"]
}
}
}
# main.tf
resource "aws_iam_role" "lambda_edge_exec" {
assume_role_policy = data.aws_iam_policy_document.lambda_edge_assume_role_policy.json
}It’s essential to specify both identifiers for Lambda@Edge functions. We will later associate this role with the function
Now, all that remains is to push the build artifacts to AWS. It’s important to note that if we intend to associate these lambdas with CloudFront as Lambda@Edge functions, we must deploy them in the us-east-1 region.
We’ll discuss more about the build process later. For the time being, let’s assume our build, or as I prefer to term it, our “packed” artifacts, are stored in a designated location. We can utilize Terraform locals to represent them in a more comprehensible format.
We can utilize Terraform locals to display them in a more comprehensible manner.
# main.tf
locals {
edge_functions = [
{
name = "prerender-proxy"
path = "${var.edge_function_path}/packages/prerender-proxy/build/index.js"
handler = "index.handler"
},
{
name = "filter-function"
path = "${var.edge_function_path}/packages/filter-function/build/index.js"
handler = "index.handler"
},
{
name = "response-handler"
path = "${var.edge_function_path}/packages/response-handler/build/index.js"
handler = "index.handler"
}
]
}
Here, I have defined functions by their names, specify their locations (build), and indicate the handler.
We’ve defined three functions here. We’ll discuss dig deeper into the specifics of each function later. For now, our primary task is to package each of them into separate zip files for deployment.
Now, we just need to define the Lambda configuration. We can employ Terraform’s count meta-argument to iterate over locals.
# main.tf
data "archive_file" "edge_function_archives" {
count = length(local.edge_functions)
type = "zip"
source_file = "${path.module}/${local.edge_functions[count.index].path}"
output_path = "${path.module}/${var.edge_function_path}/function_archives/${local.edge_functions[count.index].name}.zip"
depends_on = [null_resource.build_edge_functions]
}Here, for each function in local.edge_functions, an archive file will be created.
# main.tf
resource "aws_lambda_function" "edge_functions" {
# If the file is not in the current working directory you will need to include a
# path.module in the filename.
count = length(local.edge_functions)
filename = "${path.module}/${var.edge_function_path}/function_archives/${local.edge_functions[count.index].name}.zip"
function_name = "${local.edge_functions[count.index].name}"
handler = local.edge_functions[count.index].handler
publish = true
memory_size = 128
role = aws_iam_role.lambda_edge_exec.arn
source_code_hash = data.archive_file.edge_function_archives[count.index].output_base64sha256
runtime = "nodejs16.x"
}
resource "aws_iam_role" "lambda_edge_exec" {
assume_role_policy = data.aws_iam_policy_document.lambda_edge_assume_role_policy.json
}While each line of code is self-explanatory, it’s worth noting that we’re associating the IAM role defined earlier.
Now, we need to think a couple of steps ahead, we can’t solely rely on the lambda function names when associating them with CloudFront. We specifically need the ARN — more precisely, the ARN of a specific version. Since this will be a Terraform sub-module to be used in our static hosting module (as recalled from article 01 😉), accessing these ARNs programmatically is essential.
Hence, the ARNs will be output as follows:
# output.tf
output "function_arns" {
value = {
for function in aws_lambda_function.edge_functions :
function.function_name => function.qualified_arn
}
}Static Hosting Stack
Let’s discuss how we can associate our Lambda functions with CloudFront. For this segment, I’ll be referencing the same repository as we see in the first article. You can find it here.
First we need to import our lambda at edge module.
# edge-functions.tf
module "edge-functions" {
source = "github.com/krishanthisera/aws-edge-functions.git"
}Then we can associate our Lambda functions with our CloudFront distribution by simply referencing their names. Neat, right?
resource "aws_cloudfront_distribution" "blog_distribution" {
...
default_cache_behavior {
allowed_methods = ["GET", "HEAD"]
cached_methods = ["GET", "HEAD"]
target_origin_id = "S3-${var.bucket_name}"
lambda_function_association {
event_type = "origin-request"
lambda_arn = module.edge-functions.function_arns["prerender-proxy"]
}
lambda_function_association {
event_type = "origin-response"
lambda_arn = module.edge-functions.function_arns["response-handler"]
}
lambda_function_association {
event_type = "viewer-request"
lambda_arn = module.edge-functions.function_arns["filter-function"]
}
forwarded_values {
headers = ["x-request-prerender", "x-prerender-host"]
query_string = false
cookies {
forward = "none"
}
}
}
...
}With this, we’ve primarily addressed the Terraform and infrastructure components. Next, we’ll discuss the specifics of the edge functions, focusing especially on the business logic and it’s implementation.
Edge functions
From this point on in our discussion, I’ll be referencing the content inside the edge-functions directory of our aws-edge-functions repo.
This directory contains a monorepo for our edge functions. If you’re unfamiliar with the term “monorepo”, it stands for “monolithic repository”. In a monorepo setup, multiple projects or components of a software application are stored within a single version control repository. So instead of managing distinct repositories for every project or component, everything is centralized.
In our setup, all our Lambda@Edge functions are located in the packages directory. These functions are written in TypeScript. When we build them, the TypeScript code for each edge function is transpiled into a single JavaScript package.
We manage dependencies using one main dependency/package management file (package.json) and have a single lock file (yarn.lock).
I’ve used esbuild for the build process. If you look inside each package, you’ll find a file named esbuild.js. This file outlines how the application is built. Additionally, the package.json for each package contains the specified build script.
import { build } from "esbuild"
import fg from "fast-glob"
const define = {}
// For optional ENVs
for (const k in process.env) {
define[`process.env.${k}`] = JSON.stringify(process.env[k])
}
export const buildNode = async ({ ...args }) => {
await build({
entryPoints: await fg("src/*.ts"),
platform: "node",
target: "node16",
format: "cjs",
outdir: "./build",
sourcemap: false,
logLevel: "info",
bundle: true,
define,
...args,
})
}
await buildNode({})I’ve also used turbo-repo to aid in the build process.
There are many tools out there to assist with this, but our main focus isn’t to discuss the details of setting up a monorepo or how esbuild operates. We simply aim to transpile our TypeScript code to JavaScript so it can be used as a Lambda@Edge function.
Prerendering: The Business logic
Let’s dive into the most crucial part of our discussion.
Imagine the scenario: our website has dynamic content, but search engines prefer static HTML for indexing. Our goal is to serve static HTML, rendered from our dynamic site, to these search engines.
To visualize our workflow, refer to the previously mentioned diagram:
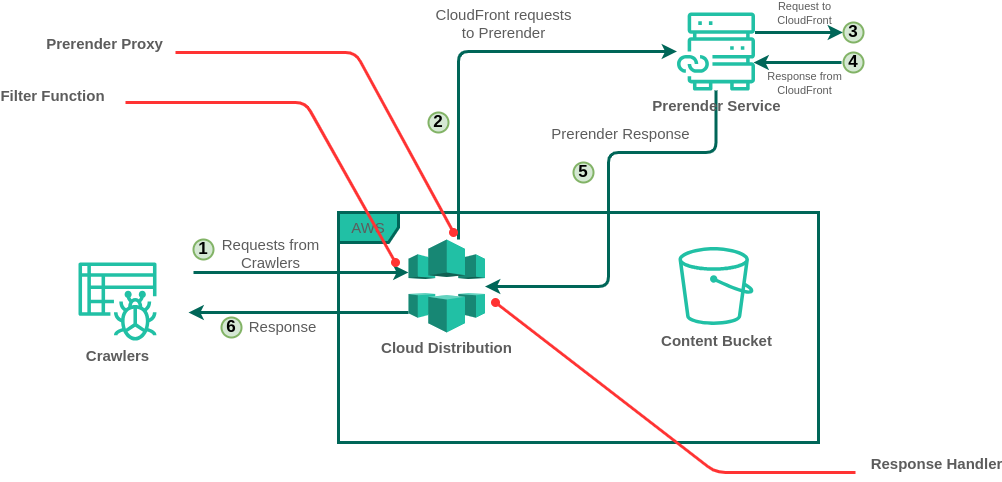
The process kicks off when our CloudFront Distribution receives a request. We need to distinguish whether this request is from a search engine crawler or a regular user.
Step 1: Filtering Requests with Lambda@Edge | Filter Function
We’ll employ a Lambda@Edge function to introduce a header, allowing us to later distinguish and appropriately handle requests during the CloudFront request flow.
Typescript handler implementation for this is not that complex 😄
// edge-functions/packages/filter-function/src/index.ts
export const handler = async (event: CloudFrontRequestEvent): Promise<CloudFrontRequest> => {
const request = event.Records[0].cf.request
// Check if the request:
// 1. Does not match any of the recognized file extensions
// 2. Is from a recognized bot user agent
// 3. Does not already have an x-prerender header
if (
!IS_FILE.test(request.uri) &&
IS_BOT.test(request.headers["user-agent"][0].value) &&
!request.headers["x-prerender"]
) {
// Set x-request-prerender header to inform origin-request Lambda function
request.headers["x-request-prerender"] = [
{
key: "x-request-prerender",
value: "true",
},
]
// Set x-prerender-host header to the host of the request
request.headers["x-prerender-host"] = [
{
key: "X-Prerender-Host",
value: request.headers.host[0].value,
},
]
}
return request
}Step 2: Requesting the Prerender Service | Prerender Proxy
Having filtered requests coming from crawlers, our next step is to ask the Prerender service to render the appropriate web page for us. This is a straightforward process: provide the webpage address and the Prerender-token from the prerender.io.
export const handler = async (event: CloudFrontRequestEvent): Promise<CloudFrontResponse | CloudFrontRequest> => {
const request = event.Records[0].cf.request
// If the request has the x-request-prerender header, it means the viewer-request function determined it should be prerendered
if (request.headers["x-request-prerender"]) {
// CloudFront alters requests for the root path to the default root object, /index.html.
// However, when prerendering the homepage, this behavior is not desired.
if (request.uri === `${PATH_PREFIX}/index.html`) {
request.uri = `${PATH_PREFIX}/`
}
// Modify the request's origin to be the prerender service
request.origin = {
custom: {
domainName: PRERENDER_URL,
port: 443,
protocol: "https",
readTimeout: 60,
keepaliveTimeout: 5,
sslProtocols: ["TLSv1", "TLSv1.1", "TLSv1.2"],
path: "/https%3A%2F%2F" + request.headers["x-prerender-host"][0].value,
customHeaders: {
"x-prerender-token": [
{
key: "x-prerender-token",
value: PRERENDER_TOKEN,
},
],
},
},
}
} else {
if (request.uri.endsWith("/")) {
request.uri += "index.html"
} else if (!request.uri.includes(".")) {
request.uri += "/index.html"
}
}
return request
}Once invoked, the Lambda@Edge function requests the Prerender service to render our website. Then Prerender service, in turn, sends a new request to our CloudFront distribution, captures the webpage (with the dynamic content), render it, and returns it as a static HTML page.
Handling Errors
What happens if the page isn’t available? Typically, we would present a default 404 page (the HTTP status code could be 404 or 2XX). However, the Prerender service, allows us to specify a status code by embedding it within the error page’s metadata:
<meta name="prerender-status-code" content="404">
You can read more about this here.
Step 3: Responding with Static HTML | Response Handler
Once the Prerender service completes its task and sends back the static HTML, our third Lambda@Edge function formats the response.
As part of this process, we also set cache control headers to dictate how the returned responses should be cached.
// edge-functions/packages/response-handler/src/index.ts
// Create an Axios client instance for HTTP requests.
// This instance is defined outside the Lambda function for reuse between calls.
const instance = axios.create({
timeout: 1000, // Set request timeout
maxRedirects: 0, // Disable following redirects
validateStatus: (status) => status === 200, // Only consider HTTP 200 as a valid response
httpsAgent: new https.Agent({ keepAlive: true }), // Use a keep-alive HTTPS agent
})
export const handler = async (event: CloudFrontResponseEvent): Promise<CloudFrontResponse> => {
const response = event.Records[0].cf.response
// If the x-Prerender-requestid header is present, set cache-control headers.
if (response.headers[`${cacheKey}`]) {
response.headers["Cache-Control"] = [
{
key: "Cache-Control",
value: `max-age=${cacheMaxAge}`,
},
]
}
// If the response status isn't 200 (OK), fetch and set a custom error page.
else if (response.status !== "200") {
try {
const res = await instance.get(errorPageUrl)
response.body = res.data
response.headers["content-type"] = [
{
key: "Content-Type",
value: "text/html",
},
]
// Remove any pre-existing content-length headers as they might contain values from the origin.
delete response.headers["content-length"]
} catch (error) {
// If fetching the custom error page fails, return the original response.
return response
}
}
return response
}It’s crucial to understand that regardless of the origin/source (S3 or Prerender), if the response isn’t a 200 status code, here we provide our own custom error page. This page is fetched on-the-fly by Axios (the web-client), which sends a request to our website’s 404 page. If you are following along with my previous article, I have get rid of the custom error page configuration from the CloudFront. See here
Wrapping it UP
We’ve discussed how to use AWS CloudFront edge functions and S3 for our static hosting needs. Our main goal? Boosting our site’s SEO prowess. We broke down how web crawlers work, comparing it to the usual browser requests. Digging deeper, we discuss the foundation of our solution. In short, this article offers a roadmap for those wanting to optimize their static sites using AWS tools.
| AWS Static Hosting (2 Part Series) |
|---|
| AWS Static Hosting - Part 01: CloudFront, S3 and Terraform |
| AWS Static Hosting - Part 02: CloudFront Edge Functions |