
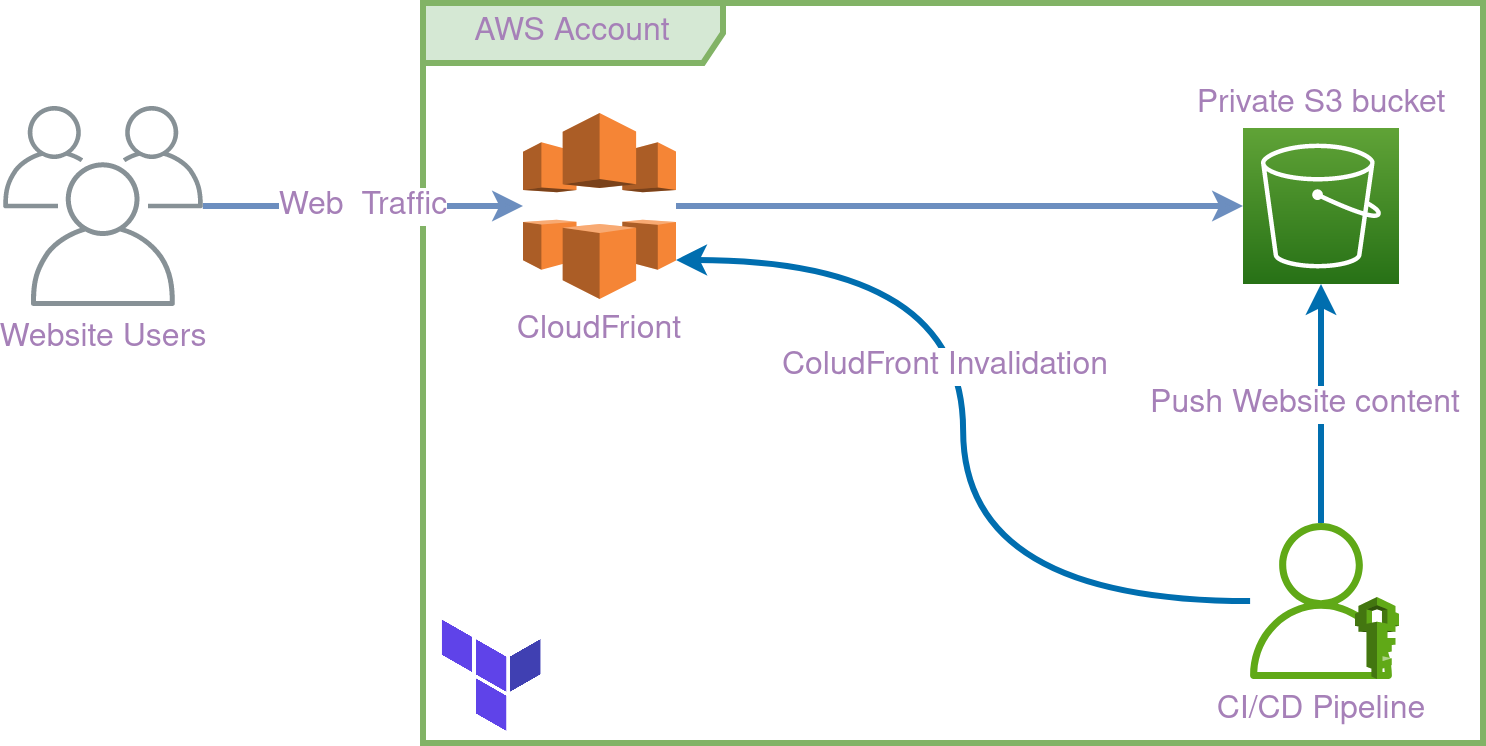
AWS Static Hosting - Part 01: CloudFront, S3 and Terraform
Depending on your requirement, There are many ways to host a website in a cloud environment. And tons of frameworks at you r disposal to get the website up and running. Here in this article, we will focus on how we can leverage AWS CloudFront and S3 to set up our static hosting infrastructure.
I am planning to discuss the scenario using two articles. In this article, we will focus primarily on infrastructure setup, and the second article would be dedicated to enhancing SEO, using Lambda at Edge functions.
| AWS Static Hosting (2 Part Series) |
|---|
| AWS Static Hosting - Part 01: CloudFront, S3 and Terraform |
| AWS Static Hosting - Part 02: CloudFront Edge Functions |
The source code for this article is available here
Before you begin
I wanted to emphasize the following, If you come from an agile background (who ain’t eh?) say these are our user stories
- We want the website to host our static content
- The content should be securely stored in an S3 bucket (no public access to the bucket)
- The traffic to the site should be secured (HTTPS)
- Leverage CloudFront to deliver the static content from the bucket
- Leverage CloudFront edge functions to support multi-page routing
- The website has its own repository and a release cycle
- Provision an IAM user to Deploy the content to the S3 bucket and invalidate the CloudFront cache
Understanding CSR and SSR
Before we jump into our Infrastructure setup, it’s crucial to understand the two primary rendering methods for web applications:
- Client-Side Rendering (CSR)
- Server-Side Rendering (SSR).
Client-Side Rendering (CSR): In CSR, the browser is responsible for rendering the content. When a user accesses the website, they receive a minimal HTML file. The browser then fetches the JavaScript, which, when executed, populates the page with content. This method is popular with Single Page Applications (SPAs) and offers a smooth user experience, especially for dynamic content.
Server-Side Rendering (SSR): With SSR, the server processes the request, renders the full page, and then sends the complete HTML content to the browser. This method is beneficial for SEO as search engines can crawl the content directly without executing JavaScript. It also provides a faster initial page load.
Factors to Consider When Choosing Between CSR and SSR
- SEO Needs: If SEO is a priority, SSR might be more suitable as it ensures that search engines can easily index your content. 💡 In our second article, we will discuss how we can address this very issue.
- Performance: CSR might introduce a slight delay before the user sees the content, as the browser needs to download and execute the JavaScript. On the other hand, SSR provides content instantly but might be resource-intensive on the server side.
- Development Complexity: CSR-based SPAs can be simpler to develop and deploy, especially when using modern frameworks. SSR might introduce additional complexities, especially when dealing with caching, state management, etc.
- User Experience: For dynamic applications where content changes frequently based on user interactions, CSR can offer a more fluid experience.
Throughout this series, our primary focus is on applications that utilize Client-Side Rendering (CSR).
Setting things up
Before we start we shall set up our terraform environment. In Terraform it is vital to maintain your state file secure. I personally prefer Terraform Cloud as the configuration is straightforward and we don’t need to worry about CI/CD (GitOps-like) setup.
First, you will need to a create Terraform cloud account here (its free). Then create a project and set up a workflow, at this point, you would need to have a GitHub account (or from any VCS provider) to maintain your infrastructure code. I am not going to show-how this, as this is very straightforward.
If you have set up your Terraform workspace correctly, you should be able to see a webhook configured in your GitHub account. If you are using a VCS other than GitHub you would need to set this webhook manually.
You can follow this to set up the backend.
If you refer to the GitHub repo, config.remote.tfbackend describe my remote backend configuration. In this case, I am using a CLI input to configure the backend.
terraform init -backend-config=config.remote.tfbackendLet’s have a quick peek into our provider’s configuration.
# provider.tf
terraform {
required_version = "~> 1.5.0"
required_providers {
aws = {
source = "hashicorp/aws"
version = "~> 5.7"
}
}
backend "remote" {}
}
provider "aws" {
region = var.aws_region
}As we have set up our remote backend and conquered the provider configuration we can start writing our code.
S3 Buckets
For this section please refer to the s3.tf.
# S3 bucket for website.
resource "aws_s3_bucket" "blog_assets" {
bucket = var.bucket_name
tags = var.common_tags
}
# S3 Bucket Policy Association
resource "aws_s3_bucket_policy" "assets_bucket_cloudfront_policy_association" {
bucket = aws_s3_bucket.blog_assets.id
policy = data.aws_iam_policy_document.s3_bucket_policy.json
}
# S3 bucket website configuration
resource "aws_s3_bucket_website_configuration" "assets_bucket_website" {
bucket = aws_s3_bucket.blog_assets.id
index_document {
suffix = "index.html"
}
error_document {
key = "404.html"
}
}
# S3 bucket ACL
resource "aws_s3_bucket_acl" "assets_bucket_acl" {
bucket = aws_s3_bucket.blog_assets.id
acl = "private"
depends_on = [aws_s3_bucket_ownership_controls.assets_bucket_acl_ownership]
}
# S3 bucket CORS configuration
resource "aws_s3_bucket_cors_configuration" "assets_bucket_cors" {
bucket = aws_s3_bucket.blog_assets.id
cors_rule {
allowed_headers = ["Authorization", "Content-Length"]
allowed_methods = ["GET", "POST"]
allowed_origins = ["https://www.${var.domain_name}", "https://${var.domain_name}"]
max_age_seconds = 3000
}
}
# Set Bucket Object ownership
resource "aws_s3_bucket_ownership_controls" "assets_bucket_acl_ownership" {
bucket = aws_s3_bucket.blog_assets.id
rule {
object_ownership = "BucketOwnerPreferred"
}
depends_on = [aws_s3_bucket_public_access_block.assets_bucket_public_access]
}
# Block public access to the bucket
resource "aws_s3_bucket_public_access_block" "assets_bucket_public_access" {
bucket = aws_s3_bucket.blog_assets.id
block_public_acls = true
block_public_policy = true
ignore_public_acls = true
restrict_public_buckets = true
}There are a couple of things to note here,
- S3 bucket website configuration: here we set the paths to our index document and error document. You can even pull this path out for and defined them as a variable.
- S3 bucket CORS configuration: CORS configuration is a pretty generic one for our scenario.
- Block public access to the bucket: we don’t want our bucket objects to be publicly available.
- Set Bucket Object ownership: To avoid complications, we set the object ownership to bucket owner.
- S3 bucket policy: here we are referring to the S3 bucket policy, which has been specified in data.tf.
Let’s take a look at the policy document. See data.tf
# S3 Bucket Policy to Associate with the S3 Bucket
data "aws_iam_policy_document" "s3_bucket_policy" {
# Deployer User access to S3 bucket
statement {
sid = "DeployerUser"
effect = "Allow"
actions = [
"s3:ListBucket"
]
principals {
type = "AWS"
identifiers = [aws_iam_user.pipeline_deployment_user.arn]
}
resources = [
"arn:aws:s3:::${var.bucket_name}"
]
}
# CloudFront access to S3 bucket
statement {
sid = "CloudFront"
effect = "Allow"
actions = [
"s3:GetObject",
"s3:ListBucket"
]
principals {
type = "Service"
identifiers = ["cloudfront.amazonaws.com"]
}
condition {
test = "StringEquals"
variable = "aws:SourceArn"
values = [
"${aws_cloudfront_distribution.blog_distribution.arn}"
]
}
resources = [
"arn:aws:s3:::${var.bucket_name}",
"arn:aws:s3:::${var.bucket_name}/*"
]
}
}
Here we are specifying two different statements.
- To let the pipeline deployer user to list the bucket
- CloudFront service to read the S3 bucket content
It is important to note that we will be using Origin Access Control (OAC) instead of legacy OAI (Origin Access Identity) to provide access to S3 bucket content to the CloudFront.
# cloudfront.tf
resource "aws_cloudfront_origin_access_control" "blog_distribution_origin_access" {
name = "blog_distribution_origin_access"
origin_access_control_origin_type = "s3"
signing_behavior = "always"
signing_protocol = "sigv4"
}See here
CloudFront
For this article, we shall keep the CloudFront configuration to a minimum. Let’s discover more when we configure the Lambda at edge functions.
aws_cloudfront_distribution
Here we specify the origin configurations, as most of them are self-explanatory I am not planning to go and explain each one of them. But I think we might need an explanation for SSL certification configuration and function association.
SSL configuration
If we refer to the repository, my certificate set up is sort of a “Bring your own certificate”, but I have put together a configuration for Email or DNS challenge validation.
Please refer to acm.tf. For Email validation use the following.
# SSL Certificate
resource "aws_acm_certificate" "ssl_certificate" {
provider = aws.acm_provider
domain_name = var.domain_name
subject_alternative_names = ["*.${var.domain_name}"]
validation_method = "EMAIL"
tags = var.common_tags
lifecycle {
create_before_destroy = true
}
}Function association
If you see src/astro.js, I have a little edge function there and it is self-explanatory. A little confession, my blog is using the Astro framework, so I grab the code to the edge function from the documentation here.
// src/astro.js
function handler(event) {
var request = event.request;
var uri = request.uri;
// Check whether the URI is missing a file name.
if (uri.endsWith("/")) {
request.uri += "index.html";
}
// Check whether the URI is missing a file extension.
else if (!uri.includes(".")) {
request.uri += "/index.html";
}
return request;
}# Edge Functions
resource "aws_cloudfront_function" "astro_default_edge_function" {
name = "default_edge_function"
runtime = "cloudfront-js-1.0"
comment = "CloudFront Functions for Astro"
publish = true
code = file("src/astro.js")
}IAM
During the deployment, the deployer user would need to:
- Push build artifacts to the S3 bucket
- Do the CloudFront invalidation
If you skim through the file, you would get a good understanding of how this has been set up.
# IAM Policy for put S3 objects
resource "aws_iam_policy" "allow_s3_put_policy" {
name = "allow_aws_s3_put"
description = "Allow Pipeline Deployment to put objects in S3"
policy = data.aws_iam_policy_document.allow_aws_s3_put.json
}
# IAM policy for cloudfront to invalidate cache
resource "aws_iam_policy" "allow_cloudfront_invalidations_policy" {
name = "allow_cloudfront_invalidate"
description = "Allow pipeline user to create CloudFront invalidation"
policy = data.aws_iam_policy_document.allow_cloudfront_invalidate.json
}
# IAM User group for Pipeline Deployment
resource "aws_iam_group" "pipeline_deployment_group" {
name = "${var.domain_name}_deployment_group"
}
# IAM Policy attachment for Pipeline Deployment - S3 PUT
resource "aws_iam_group_policy_attachment" "s3_put_group_policy_attachment" {
group = aws_iam_group.pipeline_deployment_group.name
policy_arn = aws_iam_policy.allow_s3_put_policy.arn
}
# IAM Policy attachment for Pipeline Deployment - CloudFront Invalidation
resource "aws_iam_group_policy_attachment" "cloudfront_invalidation_group_policy_attachment" {
group = aws_iam_group.pipeline_deployment_group.name
policy_arn = aws_iam_policy.allow_cloudfront_invalidations_policy.arn
}
# IAM User for Pipeline Deployment
resource "aws_iam_user" "pipeline_deployment_user" {
name = "${var.domain_name}_deployer"
}
# IAM User group membership for Pipeline Deployment
resource "aws_iam_group_membership" "deployment_group_membership" {
name = "pipeline_deployment_group_membership"
users = [
aws_iam_user.pipeline_deployment_user.name
]
group = aws_iam_group.pipeline_deployment_group.name
}We shall have two policy documents for each use case mentioned earlier,
- IAM policy for CloudFront to invalidate the cache
# data.tf: IAM policy for CloudFront to invalidate cache
data "aws_iam_policy_document" "allow_cloudfront_invalidate" {
statement {
sid = "AllowCloudFrontInvalidation"
effect = "Allow"
actions = [
"cloudfront:CreateInvalidation",
"cloudfront:GetInvalidation",
"cloudfront:ListInvalidations"
]
resources = [
"${aws_cloudfront_distribution.blog_distribution.arn}"
]
}
}- IAM Policy for managing S3 objects
# data.tf: IAM Policy for put S3 objects
data "aws_iam_policy_document" "allow_aws_s3_put" {
statement {
sid = "AllowS3Put"
effect = "Allow"
actions = [
"s3:GetObject*",
"s3:GetBucket*",
"s3:List*",
"s3:DeleteObject*",
"s3:PutObject",
"s3:PutObjectLegalHold",
"s3:PutObjectRetention",
"s3:PutObjectTagging",
"s3:PutObjectVersionTagging",
"s3:Abort*"
]
resources = [
"arn:aws:s3:::${var.bucket_name}/*"
]
}
}As they are pretty generic, I am not going dig deep, but here we are attaching those two policies, to the deployer group call {var.domain_name}_deployment_group and then create a user called ${var.domain_name}_deployer and add it to the group.
Variables
There are a couple of variables I have been using, In my case, I use terraform.tfvars file to set the bucket name and the domain name. As I am not super comfortable with sharing my AWS account ID, I have copied the certificate ARN from a previously created certificate and save it against TF_VAR_ssl_certificate_arn. You can configure these variables in Terraform Cloud.
⚠️ Don’t forget to set your AWS access key pair.
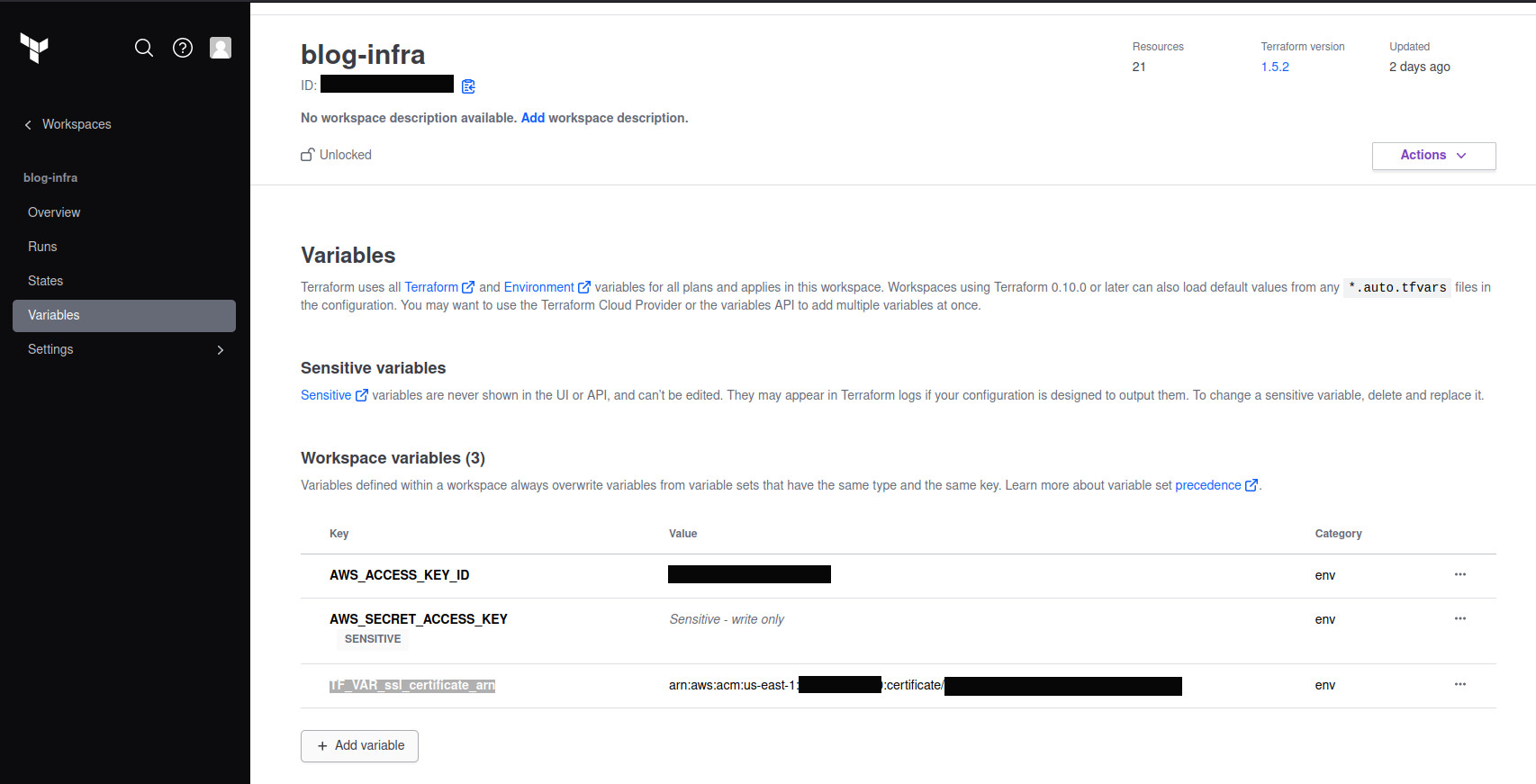
Depending on your configuration, you may either use CLI to apply the Terraform plan or, execute the plan using Terraform cloud.
Once, you’ve deployed the environment, you may need to manually create the IAM key pair using AWS Console, and use it in your CI/CD pipeline
Conclusion
In this article we discussed setting up static hosting on AWS using CloudFront, S3, and Terraform. We covered essential steps from configuring S3 buckets to setting up CloudFront distributions and managing IAM roles for security. When you set up AWS static hosting, using this systematic guide will help make your infrastructure reliable, safe, and adaptable.
| AWS Static Hosting (2 Part Series) |
|---|
| AWS Static Hosting - Part 01: CloudFront, S3 and Terraform |
| AWS Static Hosting - Part 02: CloudFront Edge Functions |